Road Segmentation and Turn Classification Using Supervised and Unsupervised Learning
Contents
- Introduction
- Dataset
- Methods
- Road Segmentation
- Supervised Turn Classification
- Conclusion and Future Work
- Contributions
- References
1. Introduction
A successful autonomous vehicle must be able to perceive its environment and use that knowledge to execute its actions. To be more specific, autonomous vehicles need to know how to identify the shape of the road they’re on. In this project, we use various machine learning techniques to identify the road from the camera image and the state estimate, and further predicts a possible steering direction based on camera images alone.
Dataset
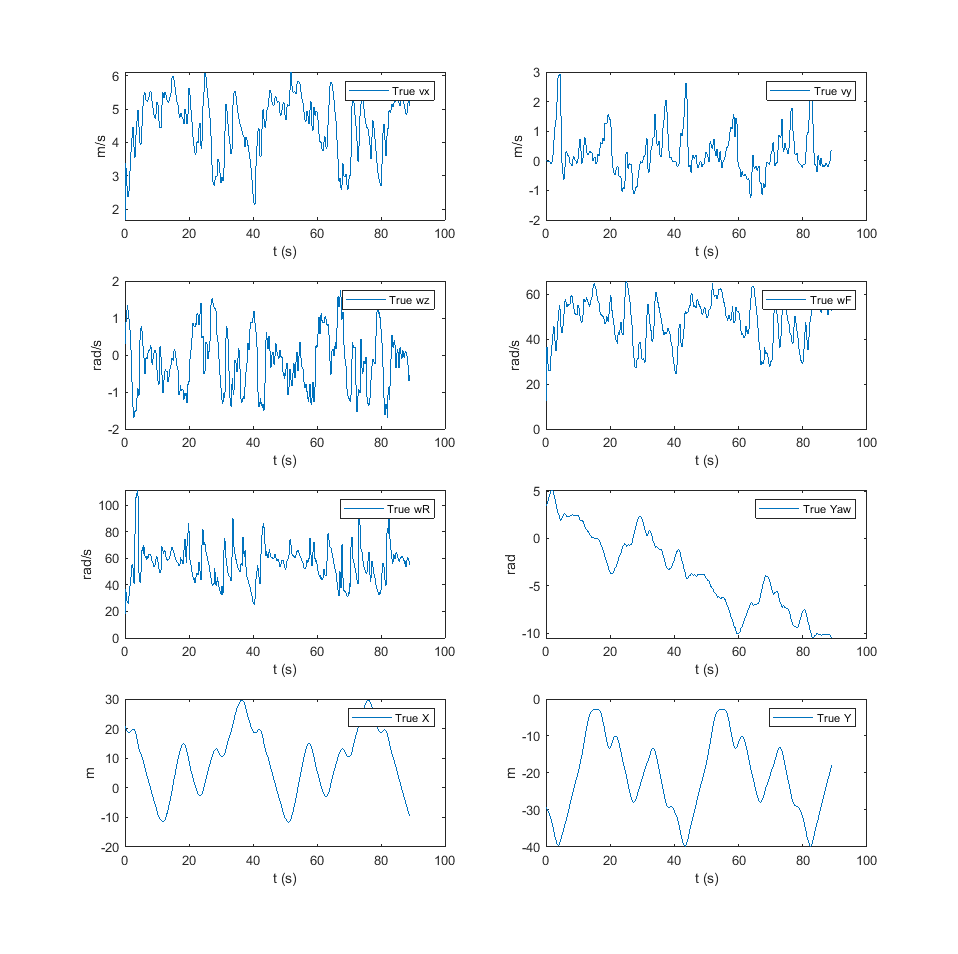
Our dataset consisted of images and state information from Georgia Tech’s AutoRally Project[1], a platform for self-driving vehicle research. Robotic cars from this project record a first-person video the area in front of them while driving around a dirt track. We selected a subset of this dataset which consists of two laps (approximately 90 seconds) of driving data. The driving data consists of images taken from the vehicle’s perspective at 40Hz as well as state estimations (such velocities in the vehicles frame and global positions) based on GPS and IMU measurements.
Below we display the state estimates for the longitudinal velocity, lateral velocity, yaw rate, front and rear wheel speeds, yaw orientation, and global X and Y positions over the 2 laps of driving data selected for the prject. We also display a couple of sample images.


Methods
Our project took the following approach to classifying whether the autorally car should turn left, right, or go straight:
- Generate a reduced representation of the road scene by segmenting the road from the image. A car’s traversable space is limited by the shape of the road they’re on, so we figured the road map would provide clear training data for a neural network.

- Use dynamics data to label each image as going left, right, or straight. This is done by filtering and thresholding the vehicle’s yaw velocity at the time each image was captured to determine the direction the car was turning.
- Train a neural network on the labelled images to classify the segmented road maps to the correct road segment types (right turn, straight, or left turn).
Road Segmentation
Road detection can be a difficult problem since the appearance of roads vary depending on lighting conditions, road texture, and the presence of obstacles. The AutoRally data provided us a simplified scene to work with: the images were taken during daytime on a dirt road with no obstacles.
We looked to two clustering algorithms to help us segment the road from the image: DBSCAN and K-Means clustering
Road Segmentation Using Unsupervised Clustering
DBSCAN
We started by trying the DBSCAN clustering algorithm on the road images. One of the advantages of DBSCAN is that it can determine the number of clusters on its own. This could be helpful in generalized road detection algorithms since we can’t always expect there to be consistent lighting conditions.
This is the overall algorithm we used:
- Pre-processing
- Crop the image to its bottom 2/3rds to ignore the sky and focus on the road.
- Apply histogram equalization to make the road stand out from the road edges and car hood.
- Blur the image to even-out the rocky appearance of the road

- Run DBSCAN to get cluster labels. We used the 3rd largest distance from a K-NN search for DBSCAN’s epsilon parameter[2].

- Use connected component analysis and a 2D Gaussian to select the cluster that has many points in the center of the image, where we assume the road to be.

Results
Despite our pre-processing steps and DBSCAN parameter tuning, we found the clusterings produced by DBSCAN to still be too sensitive to road aberrations like grass and rocks, and sometimes the road wouldn’t be selected.

Roughly half the road maps would have errors, so we looked to using K-Means
Road Segmentation Using K-Means
To apply K-Means clustering to the road segmentation problem, we made the guiding assumption that (1) light areas are sky, (2) dark areas are the car hood or road edges, and (3) midtones contain the road. This assumption is reliant on consistent lighting conditions, so it’s not generalizable to most road detection problems. For the specific data we have though, it allowed us to perform the clustering with K=3.
- Apply Gaussian Blur to smooth the road
- Run K-Means clustering on the RGB image with K=3.

- Assuming the midtone contains the road, extract it with a mask, and perform binary opening and closing to disconnect thin regions.

- Apply connected component analysis and select the largest cluster as the road. Apply further connected component analysis and flood-filling to fill in gaps in the road.

Results
Compared to DBSCAN, only about ~2% of the road maps generated by K-Means had errors in the chosen cluster. Therefore, we used this data in our neural network.

Road Segmentation Using Regularaized Learning
Predicting the road segmentation is important in real-time applications, as it projects a future planning space for the autonomous vehicle to plan and control. Unsupervised learning is computationally prohibitive to use in a real-time application of automonous driving, where the envrionment is dynamic and the onboarding computation resource is limited. On the other hand, supervised learning can provide a real-time road detection solution, once the parameters are “learned” in offline. Here we use the road labels generated by K-Means clustering to train a ridge regression model incorporating the camera image and the dynamics of the vehicle.
Image Pre-processing
Input images for the ridge regression model were pre-processed with the following methods:
- Apply Gaussian Blur to smooth the road.
- Convert to black and white image.
- Apply principal component anlaysis to attain 99.5% variance.
Ridge Regression Using Camera Image
A naive way to predict the road labels using a regression model is to use the vehicle camera image as input. However, in our experiment, training a ridge regression model based on camera images alone did not generate good predictions. The predicted road labels along with the K-means clustered road labels we used as ground truth for training are shown below.
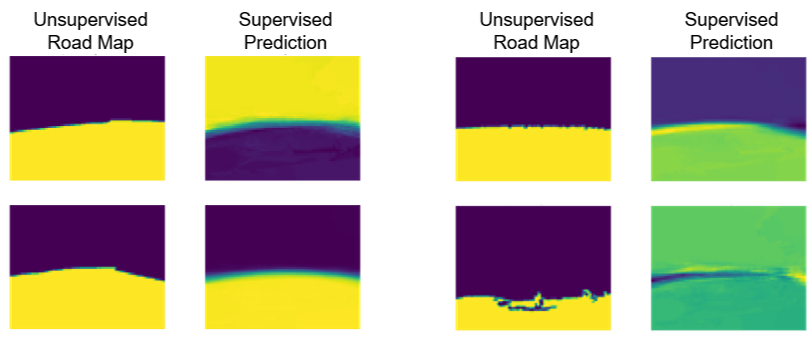
Ridge Regression Using Camera Image + Car Dynamics Data
The dynamics of the vehicle tells more than what the vehicle can “see”. We augmented the features of our image data with the AutoRally vehicle’s state and control (longitudinal velocity, lateral velocity, yaw rate, yaw position, global x position, and global y position) and (steering angle, wheel speed) respectively. As the state and control data have a strong correlation with the environment it operates, the augemented features resulted in better learning. The state and control are concatenated together with a pre-processed camera image to formulate the input to the regression model, and the K-Means road labels obtained earlier are used as ground truth labels.
The closed formulation of ridge regression was used to obtain the weight of the ridged regression model. A cross validation with k-fold was run over a series of regularization variables to find a good value. We trained with 50% of the available AutoRally data, and 10-fold was used among the training data set for the cross validation to find a good ridge parameter. The resulting weight is used to predict the road labels with given input consisting of the preprocessed image, state and control.

The predicted road segmentations are overlayed on top of the input image, and the predicted road maps alone are plotted next to the ground truth obtained with the unsupervised learning.
Supervised Turn Classification
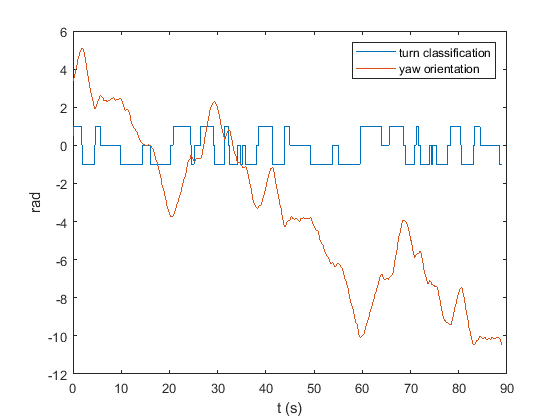
Ground Truth Steering Labels Generation
Steering labels for the training and validation datasets were generated automatically using the vehicle states information accompanying the images. We filtered the vehicle’s yaw velocity and then thresholded it to fall into one of three classes: right turns, straights, or left turns. The thresholded yaw velocity at the time each image was captured was used to provide the image labels for supervised learning. The classifications along with the measured yaw orientation are displayed below.

Decision Tree Classification
We started by using decision trees to conduct image classification on the segmented road map images. The decision tree recognizes every pixel as a feature for its tree generation process. This has turned into one of the main reasons that deciisions trees may not perform well in image classification problems. The library used was sklearn where tree has min_samples_split as a parameter to determine the minimum number of samples to split a leaf. The value assigned here is min_samples_split = 30, after trying multiple values. The output from this tree is a label (straight, right, or left).
Results
The decision tree achieved only a 37.15% accuracy, which is not good. Thus, the team has decided to move with more sophisticated classifiers such as Neural Networks to achieve better results. The figure below shows a random a sample of the results.

Neural Network Architecture
We chose to use a neural network to perform image classification on the segmented road map images. Since we have already generated our feature information in the form of the segmented roadmap, our neural network only needs to map the spatial information to the three possible labels (left turn, straight, right turn). Therefore we elected to use a series of fully connected layers to map the segmented pixel locations to the three categories. We also used one max pooling layer to reduce the image dimensionality and the number of learnable parameters in our network to speed up training. In the figure below, all intermediate fully connected layers are followed by a ReLU activation function. We also show the input and output dimensions for each layer.
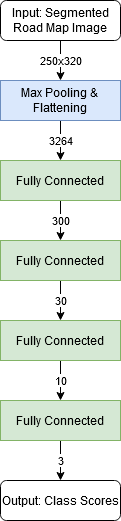
The output class scores are then fed into a softmax function for training which assigns a probability of the image belonging to each of the three classes based on the relative weight of the scores. This allows the gradient to be backpropagated through all three output channels. For validation, we simply take the argmax of the three output channels to determine the most likely class the image belongs to.
Results
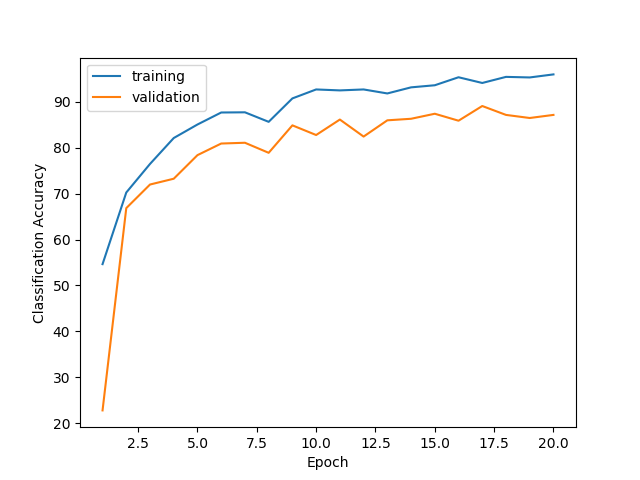
Training and Validation Accuracy
We trained the network for 20 epochs using the Adam optimizer using a cross entropy loss function. The cross entropy loss incorporates softmax which assigns a probability of the image belonging to each class based on the relative scores of the three output channels. The optimier then adjusts the layer weights to maximize the relative scores of the correct classes. We reserved one third of our dataset for validation to prevent overfitting, and plotted the training and validation accuracies for each epoch. We reach about 96% accuracy on the training data and 87% on the validation set.
Validation Examples
We demonstrate the classification results on a sample of validation images. Although the network takes the segmented images as the inputs, we display the raw, unsegmented images for easy visual inspection. The predicted and ground truth labels are displayed for each image. There is one failure case in these examples where a straight was incorrectly labeled as a right turn.

Conclusion and Future Work
Our supervised and unsupervised models were able to generate accurate road maps for over 90% of the data, but we realize they may be biased towards specific lighting conditions and road textures. In future work, we’d recommend getting more image data taken in different times of day, weather, and roads.
A decision tree didn’t work well for classifying the recommended steering direction based on the road maps, with an accuracy of only 37.15%. We had an easier time getting accurate data using a neural network containing a max pooling layer and four fully connected layers. The neural network performed with 87% validation accuracy on the validation dataset. Neural networks work well with spatial data, so we expected this result.
Group Member Contributions / Links to Project Code
- Abdulaziz Qwbaiban
- Jacob Knaup
- Prepare dataset images and state data
- Generate labels for training neural network
- Implement classification neural network in PyTorch
- Evaluate neural network performance and prepare write-up
- Jaein Lim
- Phong Tran
- Video and project page editing
- Generated road maps using DBSCAN and K-Means
References.
- Georgia Tech AutoRally Platform. https://autorally.github.io/
- Determination of Optimal Epsilon Value on DBSCAN Algorithm to Clustering Data on Peatland Hotspots in Sumatra https://iopscience.iop.org/article/10.1088/1755-1315/31/1/012012/pdf